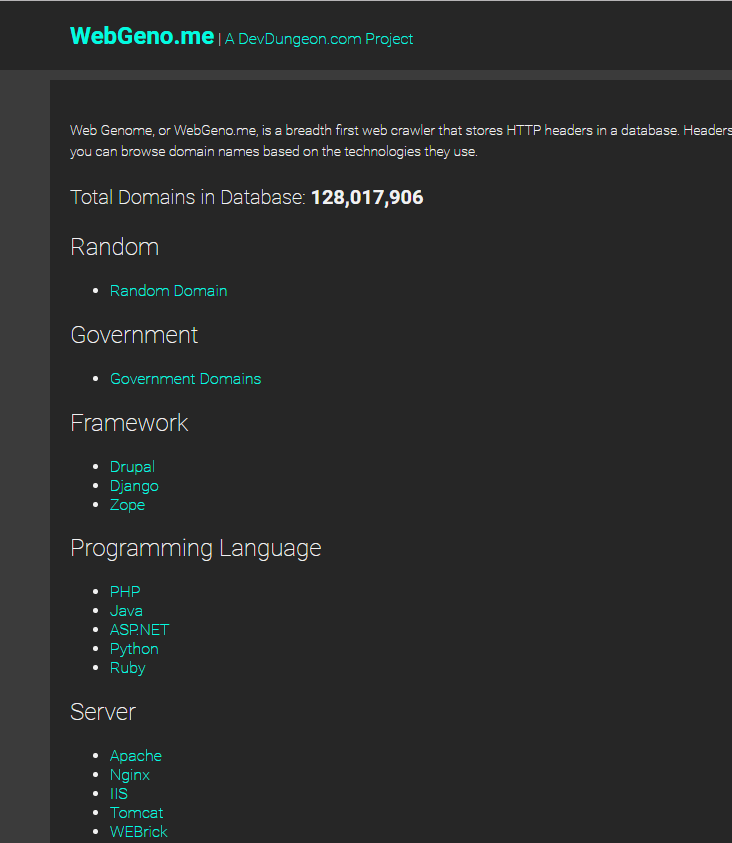
Web Genome, or www.webgeno.me, is a project that stores the HTTP headers returned from websites around the world. This information can be used for statistical analysis or fingerprinting the underlying technology.
This information can be useful for security researchers to identify numbers of unpatched servers or discover anomalous behavior. The information can also be used to identify which websites run certain web servers, program in a certain language, or use a certain content management system which can all be useful to certain marketing and sales people.
The great thing about data is that it can be useful to many different people in many different ways. The data is just data and it is all already publicly accessible. Web Genome simply archives the HTTP header responses that web servers already serve up willingly to anyone who requests them.
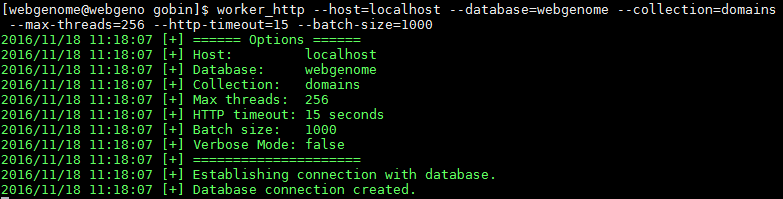
It is written in the Go programming language and uses MongoDB to store data. There is a website application and a worker that crawls the web. It is open source and you can run your own instance and contribute to the code.
Web Genome crawls the web in a breadth first fashion starting from www.devdungeon.com. Any domain found can be connected back to devdungeon.com via hyperlinks. When viewing a domain detail page, there is a "Path to DevDungeon.com" section that shows how the crawler went from devdungeon.com to that particular domain using organic hyperlinks.
Website
Source Code
The source code is available under the GPL v2 license on GitHub.
https://www.github.com/DevDungeon/WebGenome
Screenshots